Category - General
Posted - 07/14/2023 11:31am
0 Comments | Add Comment Do iPhones take pictures of you every 5 seconds?
Add a Comment
Category - Fingerprinting,Privacy,Security
Posted - 11/05/2020 02:28pm
0 Comments | Add Comment This is Your Digital Fingerprint
This piece was originally published in The Disconnect.
https://blog.mozilla.org/internetcitizen/2018/07/26/this-is-your-digital-fingerprint/
- Firefox: Control+Shift+K (or Command+Shift+K on Mac)
- Chrome: Control+Shift+J (or Command+Shift+J on Mac).
- Safari: Command+Option+C
- Edge: F12
Add a Comment
Category - Fingerprinting,Privacy,Security
Posted - 11/05/2020 02:22pm
0 Comments | Add Comment Digital Fingerprinting, What is it and why do you care?
Good article about Digital Fingerprinting from SSD
https://ssd.eff.org/en/module/what-fingerprinting#0
Fingerprinting is done extensively by tracking companies, who use this information to target users with ads or sell that information to data brokers. Digital advertising is a business worth hundreds of billions of dollars. Retargeting, or recognizing a return visitor and marketing materials based on their previous browsing, is a powerful way for marketers to increase click-through rates and generate revenue.
The most common way to retarget ads on the web is through browser cookies, and apps can use the advertiser ID provided by both iOS and Android. But the user can clear cookies and advertiser IDs to remove the persistent identifier linked to their particular browser or mobile device. Think of your browsing habits as a string that connects different pins on a board. Each pin represents a site that you've visited, and a tracker can trace that string to see what you've visited in the past. Clearing your cookies is like cutting that string into different segments, and the more often you cut the string, the smaller the segments become. The tracker can no longer see what you've visited in the past.
Fingerprinting creates a string that can't be cut by creating a new persistent identifier. It uses your browser or device characteristics against you, since the identifier is a summary of all the characteristics of your browser or device. The reason why fingerprinting exists is to circumvent the normal controls users have that enable them to control their own browsers. In order to take control of our browsers and devices back, we have to use special tools that resist fingerprinting.
First, it has to be persistent. If the user's fingerprint changes rapidly, there would be no way for the tracker to tell one visit of a user from the next visit. This ability to link visits is essential to determine that it is the same user visiting websites or using apps over time. This persistent identifier is used as a substitute for a cookie, which can be easily deleted by the user. A fingerprint can not be removed, since it does not store anything on the users' machine.
Second, it has to be unique. If two or more users have the same fingerprint, the tracker loses the ability to identify a single individual using fingerprinting. Without this ability, the tracker can not track the user individually and place them in specific marketing categories, such as "baking hobbyist" or "aircraft enthusiast." In our Panopticlick study of user browsers, launched in 2010, we discovered that the vast majority of browsers satisfied these two criteria.
In order for tools for combatting fingerprinting to be effective, they can follow one of two strategies. First, they can attempt to remove one or both of the two criteria above that make fingerprinting effective. Second, they can develop a list of trackers and block each of them from loading in the browser or on a mobile device.
There are many tools that attempt to break the persistence of fingerprints in the browser. Some will attempt to randomize the results of certain characteristics, such as a canvas fingerprint and AudioContext fingerprinting. This can be an effective method for breaking persistence, but it is important to note that a tracker may be able to determine that a randomization tool is being used, which can itself be a fingerprinting characteristic. Careful thought has to go into how randomizing fingerprinting characteristics will or will not be effective in combating trackers.
Browsers can also combat fingerprinting by making all instances of the browser look the same. By making the fingerprinting characteristics on all instances of browsers the same, a particular instance of the browser can not be uniquely pinpointed. This is the method adopted by the anonymity tool Tor Browser.
This is highly effective against fingerprinting when done right. Tor Browser has identified dozens of places where work needed to be done to make all their browsers look the same across all characteristics. This is important because it is easy for a user who is changing individual settings with the intention of throwing off trackers to actually make their browser easier for trackers to identify.
Finally, a tool can develop a list of trackers and block them directly. This is the method employed by many browser addons or extensions, such as EFFs own Privacy Badger. By blocking trackers, these tools are able to remove the bulk of the fingerprinting trackers from being loaded in the browser. Third-party trackers, which are the majority of the ones that use fingerprinting to identify users, are not able to identify user browsers.
Though this is a highly effective method to block fingerprinters, it does not completely block the ability to do fingerprinting. Sneakier trackers which haven’t been identified yet, or fingerprinting done directly by a site the user is visiting rather than by a third-party, will most commonly be permitted. This is good enough for most use cases, but does not guarantee strong anonymity.
For instance, you might be inclined to change the user-agent string, which identifies the browser and version you are using, to the most common browser user-agent string used across the web. This makes some intuitive sense: using a common user-agent string will result in a more common and less trackable fingerprint, right? In some cases, however, using the most common user-agent string will make you more fingerprintable, not less. This is counter-intuitive: how could choosing a more common metric make one stick out more?
This comes down to how independent your user-agent string is from the other fingerprintable metrics in your browser. For instance, Safari on iOS is actually a fairly non-fingerprintable browser, due to the relative similarity of hardware, software, and drivers across different devices. Most users of Safari for iOS look relatively similar.
But Safari for iOS is not the most common user-agent on the web by a long shot. Let's suppose for the moment that the latest version of Chrome for Windows is the most common user-agent. If the user were to change the user-agent string in Safari for iOS to Chrome for Windows, without changing anything else, they would appear completely unique. They would be the only one who has Safari for iOS results for canvas fingerprinting that also has the Chrome for Windows user-agent.
That's why those that are trying to avoid fingerprinting have to be extra careful that they don't accidentally hurt their privacy instead of helping it. In order to blend in, you have to join a "privacy pool" of other users that have the exact same fingerprint as you across all metrics. To do this, the safest bet is not to change settings individually, but instead to choose something like Tor Browser, Brave, or Firefox which use techniques to make all instances of their browser relatively common.
Add a Comment
Category - General
Posted - 10/01/2020 03:46pm
0 Comments | Add Comment New Quick Books Intuit Phishing Scam, BEWARE!
query to URIBL was blocked. See http://wiki.apache.org/spamassassin/DnsBlocklists#dnsbl-block for more information. [URIs: intuit.com] 0.8 BAYES_50 BODY: Bayes spam probability is 40 to 60% [score: 0.4999] 0.0 HTML_MESSAGE BODY: HTML included in message 0.5 KAM_NUMSUBJECT Subject ends in numbers excluding current years 1.0 KAM_LAZY_DOMAIN_SECURITY Sending domain does not have any anti-forgery methods 2.0 RDNS_NONE Delivered to internal network by a host with no rDNS 0.0 T_REMOTE_IMAGE Message contains an external image
X-Spam-Bar: ++++
Return-Path: <sallying@mta.notifications.intuit.com>
Return-Path: <sallying@mta.notifications.intuit.com>
- The URIBL (black list) query was blocked
- The probable spam score is 40 - 60%
- It's coming from KAM_LAZY_DOMAIN_SECURITY, which certainly isn't Intuit.
- The sending domain has no anti-forgery-methods
- There is no Return DNS information from the server
Add a Comment
Category - General
Posted - 10/01/2020 02:23pm
0 Comments | Add Comment New Apple ID Password Phishing Scam, Beware!
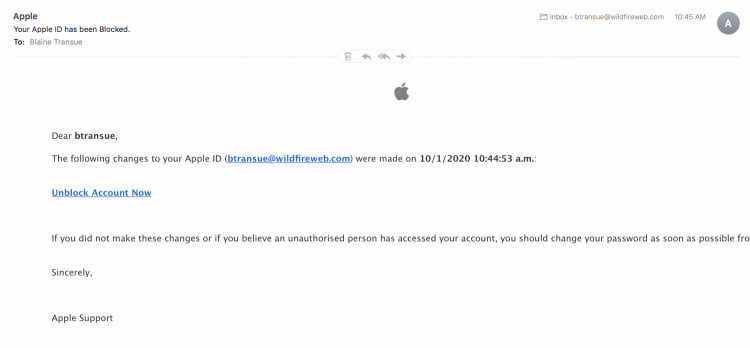


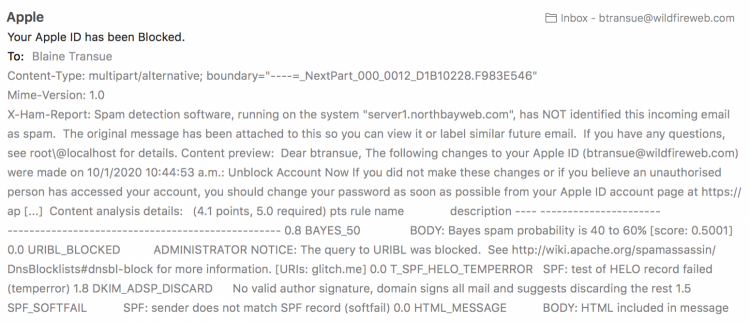
ADMINISTRATOR NOTICE: The query to URIBL was blocked. See http://wiki.apache.org/spamassassin/DnsBlocklists#dnsbl-block for more information. [URIs: glitch.me] 0.0 T_SPF_HELO_TEMPERROR SPF: test of HELO record failed (temperror) 1.8 DKIM_ADSP_DISCARD No valid author signature, domain signs all mail and suggests discarding the rest 1.5 SPF_SOFTFAIL SPF: sender does not match SPF record (softfail)
If you look a little farther in the Header you'll see something else that should make you feel confident this email didn't come from Apple, but actually from China.
Received: from server1.northbayweb.com by server1.northbayweb.com with LMTP id +PBhFM0Vdl/RDQAAKNehTQ (envelope-from <appleid@id.apple.com>) for <btransue@wildfireweb.com>; Thu, 01 Oct 2020 12:45:49 -0500
Received: from mta0.china-mail.ga ([104.168.250.214]:35319) by server1.northbayweb.com with esmtps (TLS1.2) tls TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (Exim 4.93) (envelope-from <appleid@id.apple.com>) id 1kO2e6-0000ye-8g for btransue@wildfireweb.com; Thu, 01 Oct 2020 12:45:49 -0500
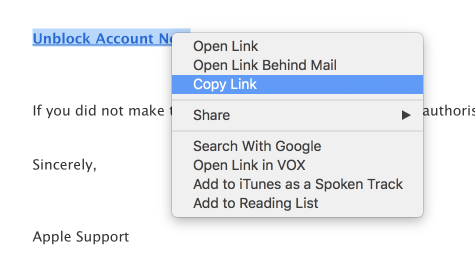
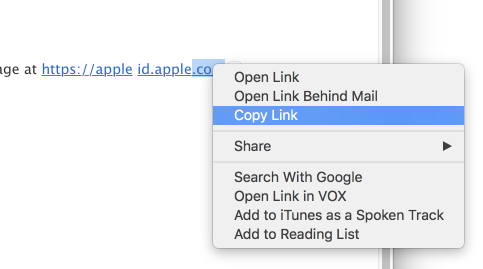
And if you dare, copy the link in the header and paste it into your browser mta0.china-mail.ga
If you did, I'm sure you found that it did not have any relationship to Apple
Add a Comment
Category - Cyber Security
Posted - 08/24/2018 05:09pm
0 Comments | Add Comment Where are you going today? It's ok, we know where you're going today
The Times Privacy Project obtained a dataset
with more than 50 billion location pings from the phones of more than
12 million people in this country. It was a random sample from 2016 and
2017, but it took only minutes — with assistance from publicly available
information — for us to deanonymize location data and track the
whereabouts of President Trump.
a senior Defense Department official told Times Opinion, even the Pentagon has told employees to expect that their privacy is compromised:
“We want our people to understand: They should make no assumptions about anonymity. You are not anonymous on this planet at this point in our existence. Everyone is trackable, traceable, discoverable to some degree.â€
We were able to track smartphones in nearly every major government building and facility in Washington. We could follow them back to homes and, ultimately, their owners’ true identities. Even a prominent senator’s national security adviser — someone for whom privacy and security are core to their every working day — was identified and tracked in the data.
https://www.nytimes.com/interactive/2019/12/20/opinion/location-data-national-security.html?utm_source=pocket-newtab
Add a Comment

Archives
- Jul 2023
- Nov 2020
- Oct 2020
- Aug 2018